重建索引(索引中间件)
当出现搜索功能或筛选器不可用、页面展示数据不符合预期等异常时,可能是索引异常,可参考本文重建。
1 影响说明
在索引重建期间,系统会逐步创建全新的索引结构。该过程采用增量式处理,数据会按批次被重新分析并加入新索引。
因此,在重建过程中:
初期阶段:新索引仅包含部分数据,搜索功能可能返回不完整的结果
中期阶段:随着处理进度推进,可检索数据量将持续增加
完成阶段:当100%数据被重新索引后,搜索功能将完全恢复正常
2 重建操作
2.1 获取ONES版本号
参考获取ONES版本号,下述相关操作分支与版本有关。
2.2 6.103.0及以上版本
进入 ones-ai-k8s 操作终端
ones-ai-k8s.sh
全量重建
make rebuild-kilob
如果确认是某个表数据异常,可以指定该表重建
make rebuild-kilob TABLES=project.item_issue
2.3 6.103.0以下版本
进入 ones-ai-k8s 操作终端
ones-ai-k8s.sh
修改配置
vi config/private.yaml
# 如下两个数字,改成跟上一次不一样的值即可;如果没有这些配置项,手工添加即可
kilobSyncSchemaHash: "2"
kilobForceSnapshotVersion: "2"
kilobForceSnapshotAll: "true"
应用配置
make setup-ones
3 查看进度与验证
3.1 日志跟踪
# kilob模块日志
kubectl logs -n ones -l app=kilob-sync --tail=200 -f
日志打印“snapshot topic: ones-cdc.project.XX, read count: XX, progress: XX%”表示该项topic的同步进度, progress为100%表示该项同步完成;当progress都为100%、不再打印progress字段时,表示索引重建完成。
# cdc模块日志
kubectl logs -f -n ones -lapp=kafka-cdc-connect --tail=200 -f
# pd模块日志
kubectl logs -f -n ones -lapp=advanced-tidb-pd --tail=200 -f
上述两个中间件日志只有INFO、没有fatal/error,表示重建过程正常;如果出现异常,请参考下文第4章FAQ处理。
3.2 索引数据对比
对比索引中的数据和数据库中的数据是否一致,一般重建后可以不用执行此步骤,但以下三种情况请执行:
- 从 Docker 迁移到 K3s 完成数据导入后;
- 迁移了服务器环境;
- 从 SaaS 迁移到私有云环境。
如果客户数据量较大(task >= 200w 或 wiki 页面 >= 200w),谨慎执行此操作。
3.2.1 v6.1.86 及以上版本数据对比
ones-ai-k8s.sh
make print-kilob-index
结果类似如下,其中page表的少量不一致可忽略:
是否重建完成: 【是】
———————————————————————————————————————————————————————————————————————
| Team/Organization Table MySQL TiKV Status |
———————————————————————————————————————————————————————————————————————
| BiUhudNp org_user 7 7 ✅ |
———————————————————————————————————————————————————————————————————————
| E4K7fDQs task 49 49 ✅ |
| E4K7fDQs project 2 2 ✅ |
| E4K7fDQs product 0 0 ✅ |
| E4K7fDQs sprint 4 4 ✅ |
| E4K7fDQs testcase_library 1 1 ✅ |
| E4K7fDQs testcase_case 2 2 ✅ |
| E4K7fDQs testcase_plan 1 1 ✅ |
| E4K7fDQs space 1 1 ✅ |
| E4K7fDQs page 21 21 ✅ |
———————————————————————————————————————————————————————————————————————
3.2.2 v6.1.86 以下版本数据对比
curl -O https://res.ones.pro/script/kilob-cli
# curl -L https://res.ones.pro/script/kilob-cli-arm64 -o kilob-cli
chmod +x kilob-cli
kubectl -n ones cp kilob-cli $(kubectl -n ones get pod -l app=ones-tools -o jsonpath='{.items[0].metadata.name}'):/
kubectl -n ones exec $(kubectl -n ones get pod -l app=ones-tools -o jsonpath='{.items[0].metadata.name}') -c ones-tools -- /kilob-cli print_index --addr advanced-tidb-pd:2379 --db $(grep mysqlHost /data/ones/ones-installer-pkg/config/private.yaml | awk '{print $2}'):3306 --db_user ones --db_password $(grep mysqlPassword /data/ones/ones-installer-pkg/config/private.yaml | awk '{print $2}')
3.3 功能验证
上述2种方法确认索引重建正常后,可登录页面查看 ONES 负责人,筛选器,文档查询功能是否正常;新增工作项、wiki页面,能否被搜索。
4 异常处理FAQ
4.1 全量重建过程中cdc模块日志报错
根据版本参考如下方式操作,然后再次执行第2章的重建操作。 同时,该方法也可较彻底的重建索引。
4.1.1 6.1--6.18.39版本重建cdc数据
kubectl -n ones scale deploy kafka-cdc-connect-deployment --replicas=0
kubectl -n ones scale deploy kilob-sync-deployment --replicas=0
kubectl -n ones scale deploy binlog-event-sync-deployment --replicas=0
kubectl -n ones scale deploy ones-bi-sync-etl-deployment --replicas=0
kubectl -n ones exec kafka-ha-0 -- /opt/bitnami/kafka/bin/kafka-topics.sh --delete --topic ones-cdc.* --bootstrap-server localhost:9092
kubectl -n ones exec kafka-ha-0 -- /opt/bitnami/kafka/bin/kafka-topics.sh --delete --topic cdc_connect.* --bootstrap-server localhost:9092
kubectl -n ones scale deploy kafka-cdc-connect-deployment --replicas=1
kubectl -n ones scale deploy kilob-sync-deployment --replicas=1
kubectl -n ones scale deploy binlog-event-sync-deployment --replicas=1
kubectl -n ones scale deploy ones-bi-sync-etl-deployment --replicas=1
4.1.2 6.18.40及以上版本重建cdc操作
ones-ai-k8s.sh
make rebuild-cdc
4.2 全量重建过程中kilob模块日志中出现mysqldump报错
# 报错样例如下:
1、mysqldump: Error 3024: Query execution was interrupted, maximum statement execution time exceeded when dumping table "field _value" at row: 26858769
2、mysqldump: Error 2013: Lost connection to MyQL server during query when dumping table`task`at row; 1545674
# 报错原因是 某些表太大,mysqldump导出时超时,需要调整默认mysql参数
# 进入mysql,调整如下参数值如下
interactive_timeout=86400
wait_timeout = 86400
max_execution_time=0
net_write_timeout=3600
net_read_timeout=3600
max_allowed_packet=5368709120
调整方式如下图,请先保存旧值、重建之后还原。
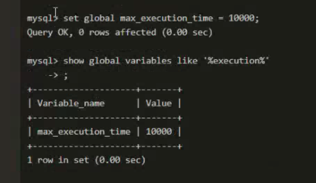
4.3 全量重建过程中kilob/cdc/canal等模块OOM
# 进入容器,调整如下内存限制值如下,可根据当前内存情况调整
ones-ai-k8s.sh
vi config/private.yaml
#V3版本如下参数
onesCanalMemoryLimit: "4Gi"
onesBISyncCanalMemoryLimit: "4Gi"
kilobSyncMemoryLimit: "16Gi"
#v6以上版本如下参数,canal模块改为cdc模块
kilobSyncMemoryLimit: "16Gi"
kafkaCdcConnectMemoryLimit: "16Gi"
make setup-ones
4.4 全量重建过程中kilob模块日志报错 raft entry is too large
重建过程中,kilob日志打印报错信息: write Kilob event error, err=message:"raft entry is too large, region 38, entry size 19895537"
故障原因是 tikv在处理超大字段数据时发生异常,需增加配置 raft-entry-max-size = "20MiB"来适配。
4.4.1 6.18及以上版本修复
ones-ai-k8s.sh
vi default/config.yaml
# 找到并调大 raft-entry-max-size 的配置
make setup-ones-built-in-tikv
kubectl rollout restart deployment/kilob-sync-deployment -n ones
## 无需再次重建索引,观察kilob日志是否更新即可
## 如果依然报错,请调大 default/config.yaml的raft-entry-max-size 配置
## 然后再次执行 make setup-ones-built-in-tikv
4.4.2 6.18 以下版本修复
ones-ai-k8s.sh
vi config/private.yaml
## 新增如下代码段的配置
## 然后使配置生效
kubectl -n ones delete tidbcluster advanced-tidb
make setup-ones-built-in-tikv
kubectl rollout restart deployment/kilob-sync-deployment -n ones
## 无需再次重建索引,观察kilob日志是否更新即可
tidbTikvConfig: |
## Memory usage limit for the TiKV instance. Generally it's unnecessary to configure it
## explicitly, in which case it will be set to 75% of total available system memory.
## Considering the behavior of `block-cache.capacity`, it means 25% memory is reserved for
## OS page cache.
##
## It's still unnecessary to configure it for deploying multiple TiKV nodes on a single
## physical machine. It will be calculated as `5/3 * block-cache.capacity`.
##
## For different system memory capacity, the default memory quota will be:
## * system=8G block-cache=3.6G memory-usage-limit=6G page-cache=2G.
## * system=16G block-cache=7.2G memory-usage-limit=12G page-cache=4G
## * system=32G block-cache=14.4G memory-usage-limit=24G page-cache=8G
##
## So how can `memory-usage-limit` influence TiKV? When a TiKV's memory usage almost reaches
## this threshold, it can squeeze some internal components (e.g. evicting cached Raft entries)
## to release memory.
memory-usage-limit = "6G"
[quota]
## Quota is use to add some limitation for the read write flow and then
[log]
## Log levels: debug, info, warn, error, fatal.
[log.file]
## Usually it is set through command line.
[readpool.unified]
## The minimal working thread count of the thread pool.
[readpool.storage]
## Whether to use the unified read pool to handle storage requests.
[readpool.coprocessor]
## Whether to use the unified read pool to handle coprocessor requests.
[server]
## Listening address.
grpc-memory-pool-quota = "2G"
[storage]
## The path to RocksDB directory.
[storage.block-cache]
## Whether to create a shared block cache for all RocksDB column families.
##
## Block cache is used by RocksDB to cache uncompressed blocks. Big block cache can speed up read.
## It is recommended to turn on shared block cache. Since only the total cache size need to be
## set, it is easier to config. In most cases it should be able to auto-balance cache usage
## between column families with standard LRU algorithm.
##
## The rest of config in the storage.block-cache session is effective only when shared block cache
## is on.
shared = true
## Size of the shared block cache. Normally it should be tuned to 30%-50% of system's total memory.
## When the config is not set, it is decided by the sum of the following fields or their default
## value:
## * rocksdb.defaultcf.block-cache-size or 25% of system's total memory
## * rocksdb.writecf.block-cache-size or 15% of system's total memory
## * rocksdb.lockcf.block-cache-size or 2% of system's total memory
## * raftdb.defaultcf.block-cache-size or 2% of system's total memory
##
## To deploy multiple TiKV nodes on a single physical machine, configure this parameter explicitly.
## Otherwise, the OOM problem might occur in TiKV.
##
## If it's not set, 45% of available system memory will be used.
capacity = "4GB"
[storage.flow-control]
## Flow controller is used to throttle the write rate at scheduler level, aiming
[storage.io-rate-limit]
## Maximum I/O bytes that this server can write to or read from disk (determined by mode)
[pd]
## PD endpoints.
# endpoints = ["127.0.0.1:2379"]
[raftstore]
## Whether to enable Raft prevote.
raft-entry-max-size = "20MiB"
[coprocessor]
## When it is set to `true`, TiKV will try to split a Region with table prefix if that Region
[coprocessor-v2]
## Path to the directory where compiled coprocessor plugins are located.
[rocksdb]
## Maximum number of threads of RocksDB background jobs.
[rocksdb.titan]
## Enables or disables `Titan`. Note that Titan is still an experimental feature.
[rocksdb.defaultcf]
## Compression method (if any) is used to compress a block.
[rocksdb.defaultcf.titan]
## The smallest value to store in blob files. Value smaller than
[rocksdb.writecf]
## Recommend to set it the same as `rocksdb.defaultcf.compression-per-level`.
[rocksdb.lockcf]
[raftdb]
[raftdb.defaultcf]
## Recommend to set it the same as `rocksdb.defaultcf.compression-per-level`.
[raft-engine]
## Determines whether to use Raft Engine to store raft logs. When it is
memory-limit = "1GB"
[security]
## The path for TLS certificates. Empty string means disabling secure connections.
[security.encryption]
## Encryption method to use for data files.
[import]
## Number of threads to handle RPC requests.
[backup]
## Number of threads to perform backup tasks.
[cdc]
old-value-cache-memory-quota="128MiB"
sink-memory-quota="128MiB"
[log-backup]
## Number of threads to perform backup stream tasks.
enable=false
[backup.hadoop]
## let TiKV know how to find the hdfs shell command.
[pessimistic-txn]
## The default and maximum delay before responding to TiDB when pessimistic
[gc]
## The number of keys to GC in one batch.
[memory]
enable-heap-profiling=false
4.5 全量重建过程中kilob或cdc模块日志报错 serialized which is larger
重建过程中,kilob日志打印报错信息:The message is 21719670 bytes when serialized which is larger than 20971520, which is the value of the max.request.size configuration.
故障原因是kafka在超大字段数据时发生异常,需调整配置 CONNECT_PRODUCER_MAX_REQUEST_SIZE 来适配。
ones-ai-k8s.sh
vi apps/ones/v1/base/k8s-v1.16/kafka-cdc-connect/kafka-cdc-connect.yaml
# 找到如下字段,将该值改大,保存
- name: CONNECT_PRODUCER_MAX_REQUEST_SIZE
value: "20971520"
# 再次执行正文的重建索引操作
4.6 全量重建过程中kilob模块日志报错 Retry to acquire the lock
重建过程中kilob日志打印一直报错信息:Retry to acquire the lock、且超过10分钟,则手工解锁
kubectl -nones scale deployment kilob-sync-deployment --replicas=0
# 进入 redis 执行
kubectl exec -it -n ones stable-redis-master-0 -- sh
redis-cli
select 11
del ones-cdc-lock
kubectl -nones scale deployment kilob-sync-deployment --replicas=1
# 等待几分钟后,观察索引日志是否已正常
# 如果依然失败, 重新执行索引重建操作
4.7 全量重建过程中kilob模块日志报错loadRegion from PD failed
可能是PD异常,尝试重建pd数据
kubectl -nones scale deployment kilob-sync-deployment --replicas=0
kubectl -n ones scale sts advanced-tidb-pd --replicas=0
kubectl -n ones scale sts advanced-tidb-tikv --replicas=0
mv /data/ones/ones-local-storage/tidb/ones/pd-advanced-tidb-pd-0 /data/ones/ones-local-storage/tidb/ones/pd-advanced-tidb-pd-0_$(date +"%Y-%m-%d-%H-%M")
mv /data/ones/ones-local-storage/tidb/ones/tikv-advanced-tidb-tikv-0 /data/ones/ones-local-storage/tidb/ones/tikv-advanced-tidb-tikv-0_$(date +"%Y-%m-%d-%H-%M")
mkdir /data/ones/ones-local-storage/tidb/ones/pd-advanced-tidb-pd-0
mkdir /data/ones/ones-local-storage/tidb/ones/tikv-advanced-tidb-tikv-0
kubectl -n ones scale sts advanced-tidb-pd --replicas=1
kubectl -n ones scale sts advanced-tidb-tikv --replicas=1
kubectl -nones scale deployment kilob-sync-deployment --replicas=1
如果重建之后还是异常,检查集群内CoreDNS是否没有关闭上游查询,可参考如下步骤进行手工关闭。需先确认客户环境没有使用域名访问,以及对接外部其他依赖域名解析的系统,如有请判断是否需要添加hostAliases。
kubectl -n kube-system edit configmap coredns
#删除forward、loop这两行,然后保存
kubectl -n kube-system delete po -l k8s-app=kube-dns
再次按照上述方法,再次重建pd数据,当pd重建完成,kilob-sync会自动重建索引。