Node故障处理
本文介绍关于 k3s/k8s Node节点异常问题的诊断流程、排查思路、常见问题及解决方案。
本文目录
诊断流程
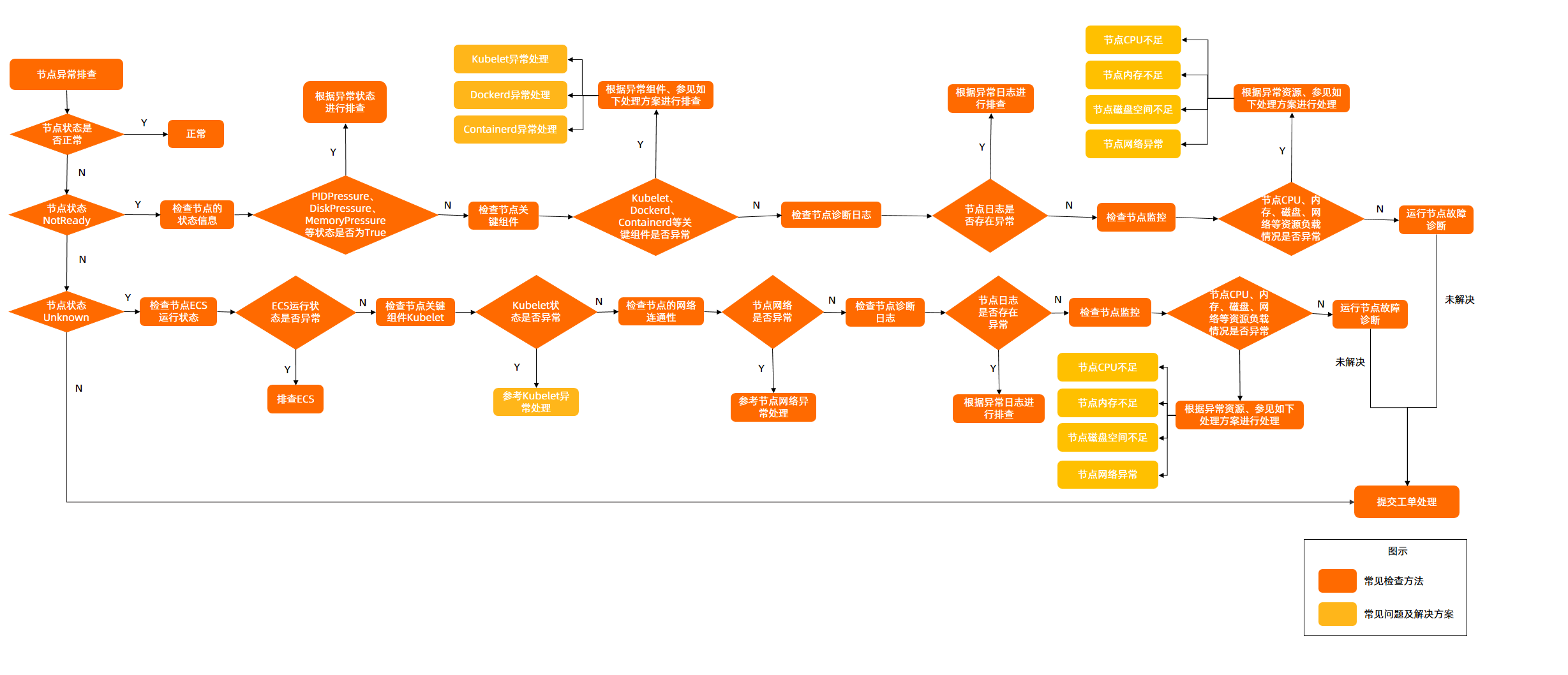
- 查看节点是否处于异常状态。具体操作,请参见检查节点的状态。
- 若节点处于NotReady状态,可参考如下步骤进行排查:
- 检查节点状态信息,查看PIDPressure、DiskPressure、MemoryPressure等节点类型的状态是否为True。若某一节点类型的状态为True,则根据相应异常状态关键字进行排查。具体操作,请参见Dockerd异常处理-RuntimeOffline、节点内存不足-MemoryPressure和节点索引节点不足-InodesPressure等进行解决。
- 检查节点的关键组件和日志。
- Kubelet
- 检查Kubelet的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键组件。
- 若Kubelet存在异常,请参见Kubelet异常处理操作。
- Dockerd
- 检查Dockerd的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键组件。
- 若Dockerd存在异常,请参见Dockerd异常处理-RuntimeOffline操作。
- Containerd
- 检查Containerd的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键组件。
- 若Containerd存在异常,请参见Containerd异常处理-RuntimeOffline操作。
- NTP
- 检查NTP服务的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键组件。
- 若NTP服务存在异常,请参见NTP异常处理-NTPProblem操作。
- Kubelet
- 检查节点的诊断日志。
- 检查节点的监控,查看节点CPU、内存、网络等资源负载情况是否存在异常。具体操作,请参见检查节点的监控。若节点负载异常,请参见节点CPU不足和节点内存不足-MemoryPressure等解决。
- 若节点处于Unknown状态,可参考如下步骤进行排查。
- 检查节点服务器实例状态是否为开机 运行中。
- 检查节点的关键组件。
- Kubelet
- 检查Kubelet的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键组件。
- 若Kubelet存在异常,请参见Kubelet异常处理操作。
- Dockerd
- 检查Dockerd的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键组件。
- 若Dockerd存在异常,参见Dockerd异常处理-RuntimeOffline操作。
- Containerd
- 检查Containerd的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键��组件。
- 若Containerd存在异常,请参见Containerd异常处理-RuntimeOffline操作。
- NTP
- 检查NTP服务的状态、日志、配置等是否存在异常。具体操作,请参见检查节点的关键组件。
- 若NTP服务存在异常,请参见NTP异常处理-NTPProblem操作。
- Kubelet
- 检查节点的网络连通性。具体操作,请参见检查节点防火墙及安全组。若节点网络存在异常,请参见节点网络异常解决。
- 检查节点的诊断日志。
- 检查节点的监控,查看节点CPU、内存、网络等资源负载情况是否存在异常。具体操作,请参见检查节点的监控。若节点负载异常,请参见节点CPU不足和节点内存不足-MemoryPressure解决。
- 若节点处于NotReady状态,可参考如下步骤进行排查:
- 若问题仍未解决,请提交工单排查。
常见排查方法
检查节点的状态
当节点出现故障时,您可以通过登录服务器,确保服务器是在线可连通状态,硬件及其他不可抗拒因素导致故障,不再排查范围内。
-
登录运维操作服务器,检查常规指标;CPU/内存/负载状态。
top -
进入ONES运维工具箱容器。
ones-ai-k8s.sh # 进入ones运维操作容器 -
查询K3S/K8S集群节点状态。
kubectl get node # 查看全部节点基本信息,检查节点状态�是否为:Ready状态
kubectl describe node <node-name>- 若状态为Ready说明节点运行正常。
检查节点的详情及事件
- 登录运维操作服务器
- 进入ONES运维工具箱容器。
ones-ai-k8s.sh # 进入ones运维操作容器 - 查询K3S/K8S集群节点详情及事件信息。
kubectl get node # 查看全部节点基本信息,检查节点状态是否为:Ready状态
kubectl describe node <node-name>
kubectl describe node <node-name> | grep -A 5 "Events" # 这将提供有关节点事件的详细描述,包括事件的类型、原因、消息和产生事件的时间,通过分析节点的事件状态,您可以更全面地了解节点上发生的任何异常情况,从而有针对性地进行故障排查和修复。
若节点处于NotReady状态,可参考如下步骤进行排查:
检查节点状态信息,查看PIDPressure、DiskPressure、MemoryPressure等节点类型的状态是否为True。若某一节点类型的状态为True,则根据相应异常状态关键字进行排查。具体操作,请参见Dockerd异常处理-RuntimeOffline、节点内存不足-MemoryPressure和节点索引节点不足-InodesPressure等进行解决。
检查节点的关键组件
-
Kubelet (k8s deploy):
-
查看Kubelet状态
登录对应节点,在节点上执行如下命令,查看Kubelet进程状态。
systemctl status kubelet预期输出:
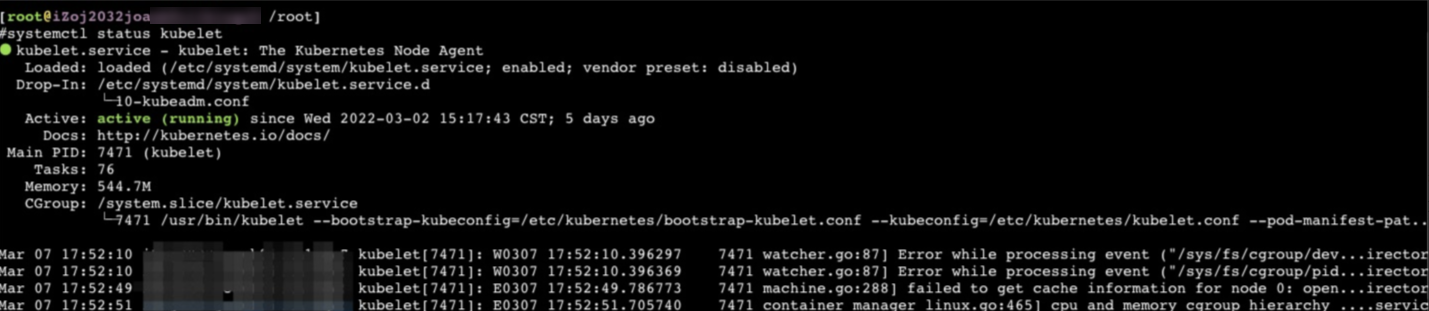
-
查看Kubelet日志
登录对应节点,在节点上执行如下命令,可查看Kubelet日志信息。
journalctl -u kubelet -
查看Kubelet配置
登录对应节点,在节点上执行如下命令,可查看Kubelet配置信息。
cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
-
-
k3s (k3s deploy):
-
查看k3s状态
登录对应节点,在节点上执行如下命令,查看Kubelet进程状态。
k3s check-config # 运行 check-config 并确保它通过
systemctl status k3s -
查看k3s日志
登录对应节点,在节点上执行如下命令,可查看Kubelet日志信息。
journalctl -u k3s -
查看k3s配置
登录对应节点,在节点上执行如下命令,可查看Kubelet配置信息。
cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
-
-
运行时:
-
检查Dockerd
-
查看Dockerd状态
登录对应节点,在节点上执行如下命令,查看Dockerd进程状态。
systemctl status docker -
查看Dockerd日志
登录对应节点,在节点上执行如下命令,可查看Dockerd的日志信息。
journalctl -u docker -
查看Dockerd配置
登录对应节点,在节点上执行如下命令,可查看Dockerd配置信息。
cat /etc/docker/daemon.json
-
-
检查Containerd
-
查看Containerd状态
登录对应节点,在节点上执行如下命令,查看Containerd进程状态。
systemctl status containerd -
查看Containerd日志
登录对应节点,在节点上执行如下命令,可查看Containerd日志信息。
more /var/lib/rancher/k3s/agent/containerd/containerd.log # 查看所有日志
journalctl -u containerd
-
-
-
检查NTP:
-
查看NTP服务状态
登录对应节点,在节点上执行如下命令,查看Chronyd进程的状态。
systemctl status chronyd预期输出:
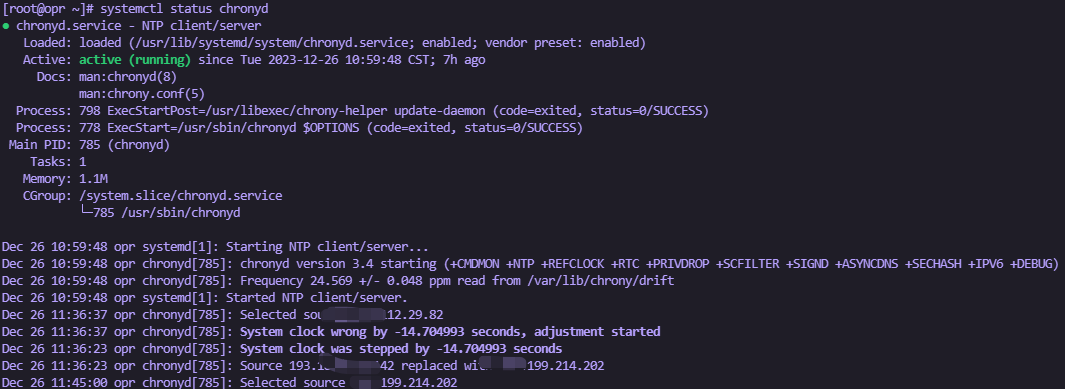
-
查看NTP服务日志
登录对应节点,在节点上执行如下命令,可查看NTP日志信息。
journalctl -u chronyd
-
检查节点的监控
-
服务器监控
可以通过云厂商/私有云提供的基础监控服务,查看相关服务器指标。
-
ONES 周边Prometheus监控系统
- 登录Grafana 监控面板
- 在控制台Dashboard选择 搜索 "
nodeordocker"关键词
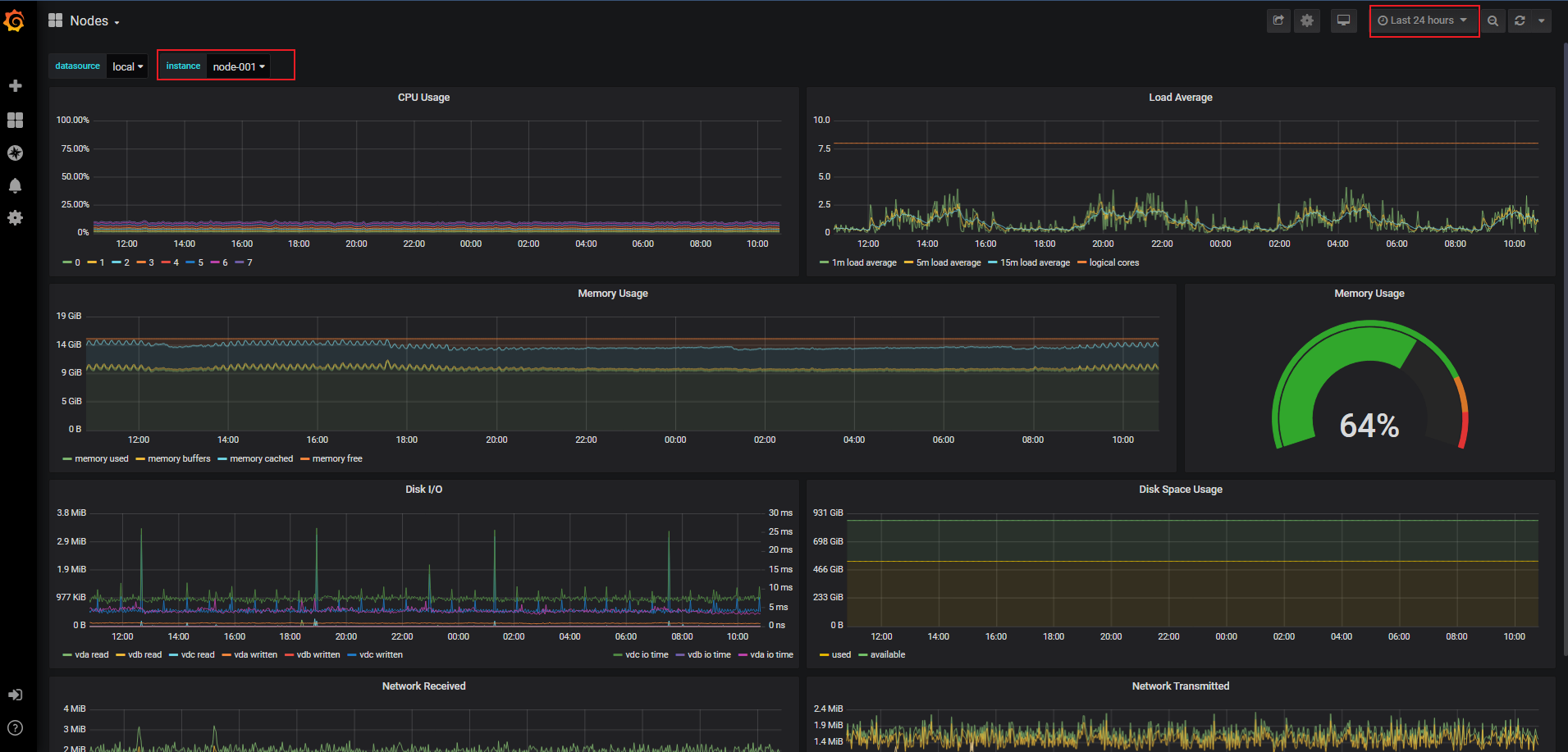
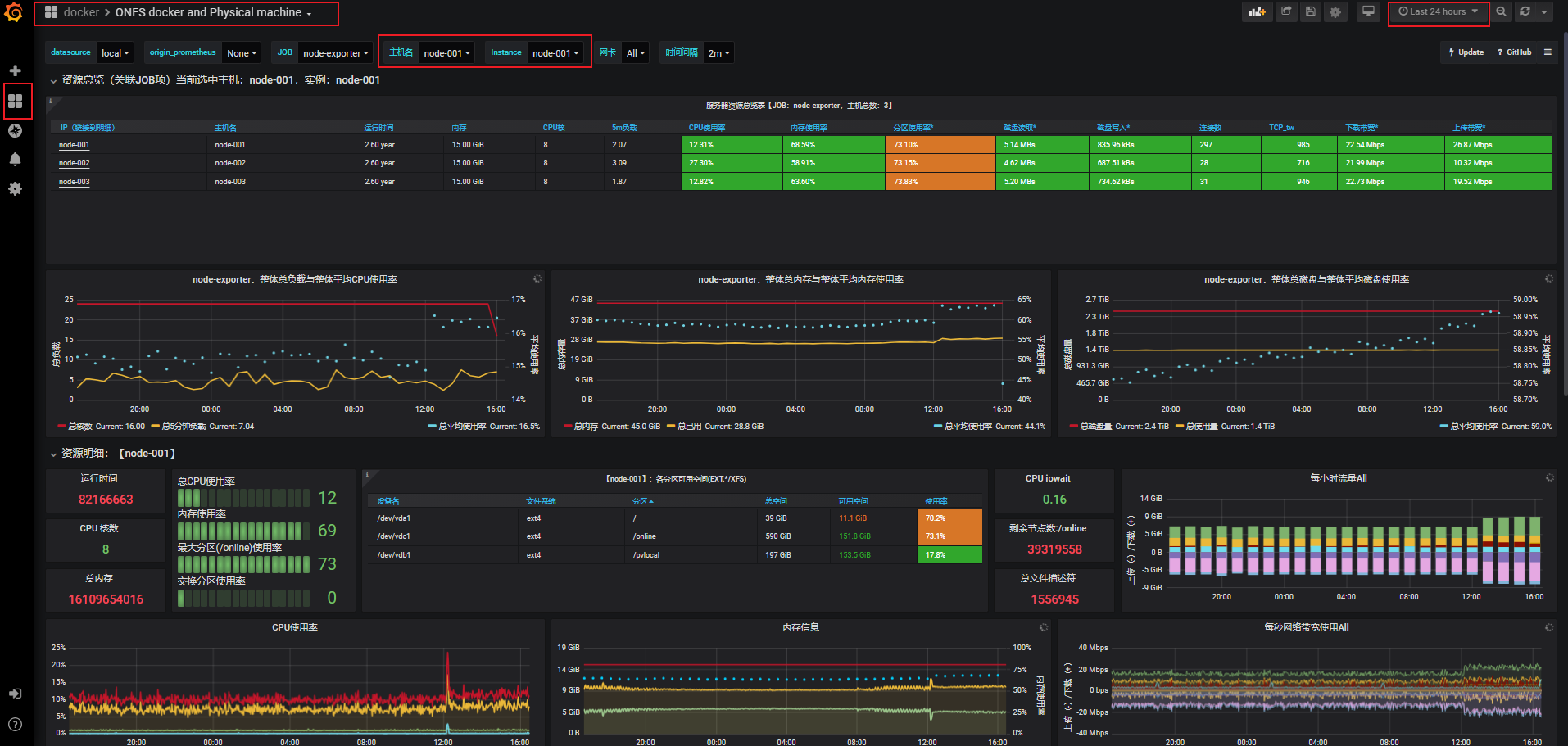
- 在Grafana Dashboard页面,选择相应instance节点实例,查看对应常规节点的CPU、内存、磁盘、网络等监控信息及时间维度趋势状态。
检查节点防火墙及安全组
关于检查服务器节点防火墙及安全组需要放行哪些端口,�请参见部署环境要求和最小化集群访问规则。
Kubelet异常处理
问题原因
通常是Kubelet进程异常、运行时异常、Kubelet配置有误等原因导致。
问题现象
Kubelet状态为inactive。
解决方案
-
执行如下命令重启Kubelet。重启Kubelet不会影响运行中的容器。
systemctl restart kubelet -
Kubelet重启后,登录节点执行以下命令,再次查看kubelet状态是否恢复正常。
systemctl status kubelet -
若Kubelet重启后状态仍异常,请登录节点执行以下命令查看Kubelet日志。
journalctl -u kubelet-
若日志中有明确的异常信息,请根据异常关键字进行排查。
-
若确认是Kubelet配置异常,请执行如下命令修改Kubelet配置。
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf #修改Kubelet配置。
systemctl daemon-reload;systemctl restart kubelet #重新加载配置并重启Kubelet。
-
Dockerd异常处理-RuntimeOffline
问题原因
通常是Dockerd配置异常、进程负载异常、节点负载异常等原因导致。
问题现象
- Dockerd状态为inactive。
- Dockerd状态为active (running),但未正常工作,导致节点异常。通常有
docker ps、docker exec等命令执行失败的现象。 - 节点状态中RuntimeOffline为True。
解决方案
-
执行如下命令重启Dockerd。
systemctl restart docker -
Dockerd重启后,登录节点执行以下命令,再次查看Dockerd状态是否恢复正常。
systemctl status docker -
若Dockerd重启后状态仍异常,请登录节点执行以下命令查看Dockerd日志。
journalctl -u docker
Containerd异常处理-RuntimeOffline
问题原因
通常是Containerd配置异常、进程负载异常、节点负载异常等原因导致。
- Containerd状态为inactive。
- 节点状态中RuntimeOffline为True。
解决方案
-
执行如下命令重启Containerd。
systemctl restart containerd -
Containerd重启后,登录节点执行以下命令,再次查看Containerd状态是否恢复正常。
systemctl status containerd -
若Containerd重启后状态仍异常,请登录节点执行以下命令查看Containerd日志。
journalctl -u containerd
more /var/lib/rancher/k3s/agent/containerd/containerd.log
NTP异常处理-NTPProblem
问题原因
通常是NTP进程状态异常导致。
问题现象
- Chronyd状态为inactive。
- 节点状态中NTPProblem为True。
解决方案
-
执行如下命令重启Chronyd。
systemctl restart chronyd -
Chronyd重启后,登录节点执行以下命令,再次查看Chronyd状态是否恢复正常。
systemctl status chronyd -
若Chronyd重启后状态仍异常,请登录节点执行以下命令查看Chronyd日志。
journalctl -u chronyd
节点PLEG异常-PLEG is not healthy
问题原因
Pod生命周期事件生成器PLEG(Pod Lifecycle Event Generator)会��记录Pod生命周期中的各种事件,如容器的启动、终止等。PLEG is not healthy异常通常是由于节点上的运行时进程异常或者节点Systemd版本缺陷导致。
问题现象
-
节点状态NotReady。
-
在Kubelet日志中,可看到如下日志。
I0729 11:20:59.245243 9575 kubelet.go:1823] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m57.138893648s ago; threshold is 3m0s.
解决方案
-
依次重启节点关键组件Dockerd、Contatinerd、Kubelet,重启后查看节点是否恢复正常。
-
若节点关键组件重启后节点仍未恢复正常,可尝试重启异常节点。
警告
重启节点可能会导致您的业务中断,请谨慎操作。
-
若异常节点系统为CentOS 7.6 systemd-219-62.el7_6.6.x86_64软件包存在缺陷依赖包已知问题,请尝试升级systemd。
节点调度资源不足
问题原因
通常是集群中的节点资源不足导致。
问题现象
当集群中的节点调度资源不足时,会导致Pod调度失败,出现以下常见错误信息:
- 集群CPU资源不足:0/2 nodes are available: 2 Insufficient cpu
- 集群内存资源不足:0/2 nodes are available: 2 Insufficient memory
- 集群临时存储不足:0/2 nodes are available: 2 Insufficient ephemeral-storage
其中调度器判定节点资源不足的计算方式为:
- 集群节点CPU资源不足的判定方式:当前Pod请求的CPU资源总量>(节点可分配的CPU资源总量-节点已分配的CPU资源总量)
- 集群节点内存资源不足的判定方式:当前Pod请求的内存资源总量>(节点可分配的内存资源总量-节点已分配的内存资源总量)
- 集群节点临时存储不足的判定方式:当前Pod请求的临时存储总量>(节点可分配的临时存储总量-节点已分配的临时存储总量)
如果当前Pod请求的资源总量大于节点可分配的资源总量减去节点已分配的资源总量,Pod就不会调度到当前节点。
执��行以下命令,查看节点的资源分配信息:
kubectl describe node [$nodeName]
关注输出中的如下部分::
Allocatable:
cpu: 3900m
ephemeral-storage: 114022843818
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 12601Mi
pods: 60
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 725m (18%) 6600m (169%)
memory 977Mi (7%) 16640Mi (132%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
其中:
- Allocatable:表示本节点可分配的(CPU/内存/临时存储)资源总量。
- Allocated resources:表示本节点已经分配的(CPU/内存/临时存储)资源总量。
解决方案
当节点调度资源不足时,需降低节点负载,方法如下:
- 删除或减少不必要的Pod,降低节点的负载。
- 根据自身业务情况,限制Pod的资源配置 重新修改limit。
- 为节点扩容进行升配。
- 在集群中添加新的节点。
更多信息,请参见节点CPU不足、节点内存不足-MemoryPressure和节点磁盘空间不足-DiskPressure。
节点CPU不足
问题原因
通常是节点上的容器占用CPU过多导致节点的CPU不足。
问题现象
- 当节点CPU不足时,可能会导致节点状态异常。
- 若集群部署配置了Alertmanager报警服务,则节点CPU使用率上线limit阈值可收到相关报警。关于告警说明,请参见Alert故障处理 Cputhrottlinghigh。
解决方案
-
通过节点的监控查看CPU增长曲线,确认异常出现时间点,检查节点上的进程是否存在CPU占用过高的现象。具体操作,请参见检查节点的监控。
-
降低节点的负载,具体操作,请参见节点调度资源不足。
-
如需重启节点,可尝试软重启异常节点。
警告
重启节点可能会导致您的业务中断,请谨慎操作。
节点内存不足-MemoryPressure
问题原因
通常是节点上的容器占用内存过多导致节点的内存不足。
问题现象
- 当节点的可用内存低于
memory.available配置项时,则节点状态中MemoryPressure为True,同时该节点上的容器被驱逐。关于节点驱逐,请参见节点压力驱逐。 - 当节点内存不足时,会有以下常见错误信息:
- 节点状态中MemoryPressure为True。
- 当节点上的容器被驱逐时:
- 在被驱逐的容器事件中可看到关键字The node was low on resource: memory。
- 在节点事件中可看到关键字attempting to reclaim memory。
- 可能会导致系统OOM异常,当出现系统OOM异常时,节点事件中可看到关键字System OOM。
- 若集群部署配置了Alertmanager报警服务,则节点内存使用率>=85%时可收到相关报警。关于告警说明,请参见Alert故障处理 NodeHighMemory。
解决方案
-
通过节点的监控查看内存增长曲线,确认异常出现时间点,检查节点上的进程是否存在内存泄漏现象。具体操作,请参见检查节点的监控。
-
降低节点的负载,具体操作,请参见节点调度资源不足。
-
如需重启节点,可尝试软重启异常节点。
警告
重启节点可能会导致您的业务中断,请谨慎操作。
节点索引节点不足-InodesPressure
问题原因
通常是节点上的容器占用索引节点过多导致节点的索引节点不足。
问题现象
- 当节点的可用索引节点低于
inodesFree配置项时,则节点状态中InodesPressure为True,同时该节点上的容器被驱逐。关于节点驱逐,请参见节点压力驱逐。 - 当节点索引点不足时,通常会有以下常见错误信息:
- 节点状态中InodesPressure为True。
- 当节点上的容器被驱逐时:
- 被驱逐的容器事件中可看到关键字The node was low on resource: inodes。
- 节点事件中可看到关键字attempting to reclaim inodes。
- 若集群部署配置了Alertmanager报警服务,则节点索引节点不足/空间不足时可收到相关报警。
解决方案
- 通过节点的监控查看索引节点增长曲线,确认异常出现时间点,检查节点上的进程是否存在占用索引节点过多现象。具体操作,请参见检查节点的监控。
- 其他问题相关操作,请参见Linux实例磁盘空间满和inode满的问题排查方法。
节点PID不足-NodePIDPressure
问题原因
通常是节点上的容器占用PID过多导致节点的PID不足。
问题现象
- 当节点的可用PID低于
pid.available配置项时,则节点状态中NodePIDPressure为True,同时该节点上的容器被驱逐。关于节点驱逐,请参见节点压力驱逐。 - 若集群部署配置了Alertmanager报警服务,则节点PID不足时可收到相关报警。
解决方案
-
执行如下命令,查看节点的最大PID数和节点当前的最大PID。
sysctl kernel.pid_max #查看最大PID数。
ps -eLf|awk '{print $2}' | sort -rn| head -n 1 #查看当前的最大PID。 -
执行如下命令,查看占用PID最多的前5个进程。
ps -elT | awk '{print $4}' | sort | uniq -c | sort -k1 -g | tail -5预期输出:
#第一列为进程占用的PID数,第二列为当前进程号。
73 9743
75 9316
76 2812
77 5726
93 5691 -
根据进程号找到对应进程和所属的Pod,分析占用PID过多的原因并优化对应代码。
-
降低节点的负载。具体操作,请参见节点调度资源不足。
-
如需重启节点,可尝试软重启异常节点。
警告
重启节点可能会导致您的业务中断,请谨慎操作。
节点磁盘空间不足-DiskPressure
问题原因
通常是节点上的容器占用磁盘过多、镜像文件过大导致节点的磁盘空间不足。
问题现象
- 当节点的可用磁盘空间低于
imagefs.available配置项时,则节点状态中DiskPressure为True。 - 当可用磁盘空间低于
nodefs.available配置项时,则该��节点上的容器全部被驱逐。关于节点驱逐,请参见节点压力驱逐。 - 当磁盘空间不足时,通常会有以下常见错误信息:
- 节点状态中DiskPressure为True。
- 当触发镜像回收策略后,磁盘空间仍然不足以达到健康阈值(默认为80%),在节点事件中可看到关键字failed to garbage collect required amount of images。
- 当节点上的容器被驱逐时:
- 被驱逐的容器事件中可看到关键字The node was low on resource: [DiskPressure]。
- 节点事件中可看到关键字attempting to reclaim ephemeral-storage或attempting to reclaim nodefs。
- 若集群部署配置了Alertmanager报警服务,则节点磁盘使用率>=85%时可收到相关报警。关于告警说明,请参见Alert故障处理 NodeFilesystemAlmostOutOfSpace。
解决方案
- 通过节点的监控查看磁盘增长曲线,确认异常出现时间点,检查节点上的进程是否存在占用磁盘空间过多的现象。具体操作,请参见检查节点的监控。
- 若有大量文件在磁盘上未清理,请清理文件。具体操作,请参见Linux实例磁盘空间满和inode满的问题排查方法。
- 根据自身业务情况,限制Pod的
ephemeral-storage资源配置。 - 建议使用对象存储,尽量避免使用HostPath数据卷。
- 节点磁盘扩容。
- 降低节点的负载。具体操作,请参见节点调度资源不足。
节点IP资源不足-InvalidVSwitchId.IpNotEnough
问题原因
通常是节点上的容器数过多导致IP资源不足。
问题现象
-
Pod启动失败,状态为ContainerCreating。检查Pod的日志有类似如下报错,包含错误信息关键字InvalidVSwitchId.IpNotEnough。关于查看Pod日志的具体操作,请参见检查Pod的日志。
time="2020-03-17T07:03:40Z" level=warning msg="Assign private ip address failed: Aliyun API Error: RequestId: 2095E971-E473-4BA0-853F-0C41CF52651D Status Code: 403 Code: InvalidVSwitchId.IpNotEnough Message: The specified VSwitch \"vsw-AAA\" has not enough IpAddress., retrying"
解决方案
降低节点上的容器数量。具体操作,请参见节点调度资源不足。其他相关操作,请完成Ip资源扩容。
节点网络异常
问题原因
通常是节点运行状态异常、安全组配置有误或网络负载过高导致。
问题现象
- 节点无法登录。
- 节点状态Unknown。
解决方案
- 若节点无法登录,请参考以下步骤进行排查:
- 检查服务器节点实例状态是否为开机 运行中。
- 检查节点的安全组配置。具体操作,请参见检查节点防火墙及安全组。
- 若节点的网络负载过高,请参考以下步骤进行排查:
- 通过节点的监控查节点网络增长曲线,检查节点上的Pod是否存在占用网络带宽过多的现象。具体操作,请参见检查节点的监控。
节点异常重启
问题原因
通常是节点负载异常等原因导致。
问题现象
- 在节点重启的过程中,节点状态为NotReady。
解决方案
-
执行以下命令,查看节点重启时间。
last reboot预期输出:

-
查看节点的监控,根据重启时间排查出现异常的资源。具体操作,请参见检查节点的监控 。
-
查看节点的内核日志,根据重启时间排查异常日志。
如何解决auditd进程占用大量磁盘IO或者系统日志中出现audit: backlog limit exceeded错误的问题
问题原因
部分集群的存量节点上默认配置了Docker相关的auditd审计规则,当节点使用了Docker容器运行时,这些审计规则会触发系统记录Docker操作相关的审计日志。在某些情况下(节点上大量容器集中反复重启、容器内应用短时间内写入海量文件、内核Bug等),会低概率出现系统大量写入审计日志影响节点磁盘IO,进而出现auditd进程占用大量磁盘IO的现象或者系统日志中出现audit: backlog limit exceeded错误的问题。
问题现象
该问题只影响使用Docker容器运行时的节点。当您在节点上执行相关命令时,具体的问题现象如下:
- 执行iotop -o -d 1命令时,结果显示auditd进程的
DISK WRITE指标持续大于或等于1MB/s。 - 执行dmesg -d命令时,结果中存在包含关键字
audit_printk_skb的日志。比如audit_printk_skb: 100 callbacks suppressed。 - 执行dmesg -d命令时,结果中存在关键字
audit: backlog limit exceeded。
解决方案
您可以通过以下操作,检查您的节点中出现的以上问题是否与节点的auditd配置有关:
-
登录集群节点。
-
执行以下命令,检查auditd规则。
sudo auditctl -l | grep -- ' -k docker'如果该命令的输出中包含如下信息,说明该节点出现的问题与auditd配置有关。
-w /var/lib/docker -k docker
如果通过以上检查确认是该问题影响了集群节点,您可以选择以下三种解决方案的任一方案解决问题。
-
升级集群版本
您可以通过升级集群版本到下一个大版本的方法来修复该问题。
-
使用Containerd容器运行时
对于无法升级的集群,可以通过使用Containerd代替Docker作为节点容器运行时的方法规避该问题。需要对每个使用Docker容器运行时的节点池进行如下操作:
- 通过克隆节�点池的方式新建一个以Containerd为容器运行时的节点池,同时确保新节点池除容器运行时配置外的其他配置都与被克隆的目标节点池保持一致。
- 在业务低峰期对目标节点池内的节点逐个进行排空节点操作,确保已无业务服务部署在目标节点池中。
-
更新节点上的auditd配置
对于无法升级集群也不能使用Containerd容器运行时的场景,可以通过手动更新节点上的auditd配置的方法规避该问题。需要对每个使用Docker容器运行时的节点进行如下操作:
说明
-
登录服务器节点实例。
-
执行以下命令,删除Docker相关的auditd规则。
sudo test -f /etc/audit/rules.d/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/rules.d/audit.rules
sudo test -f /etc/audit/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/audit.rules -
执行以下命令,应用新的auditd规则。
if service auditd status |grep running || systemctl status auditd |grep running; then
sudo service auditd restart || sudo systemctl restart auditd
sudo service auditd status || sudo systemctl status auditd
fi
-
📄️ POD故障处理
本文介绍关于 k3s/k8s Pod异常问题的诊断流程、排查方法、常见问题及解决方案。
📄️ Alert故障处理
本文介绍关于 k3s/k8s 常见告警主题处理及解决方案。
📄️ ONES故障处理
本文介绍关��于 ONES 常见场景故障处理及解决方案。
📄️ ONES混沌测试
本文基于混沌工程实践,针对 ONES v6.18.x(K3S HA + Longhorn)的集群环境,通过注入服务中断、网络延迟、资源耗尽等典型故障场景,系统性验证系统容错能力。测试结果已转化为可操作的运维知识库,为日常故障预处置提供现象级参考依据。