Alert故障处理
本文介绍关于 k3s/k8s 常见告警主题处理及解决方案。
本文目录
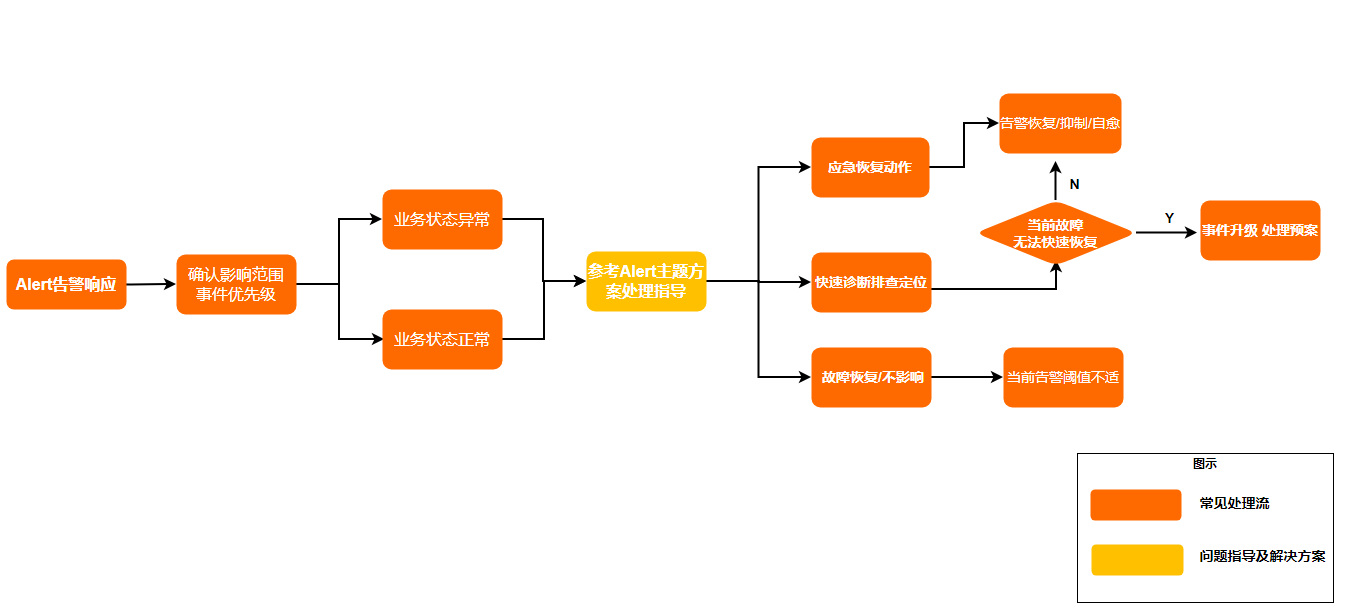
处理流程
告警列表及优先级说明
ONES对告警进行优先级划分使用的是priority, 优先级从高到低为P0、P1、P2、P3、P4
- P0 要立刻处理的严重告警,可能已经发生了严重的集群整体不可用的问题
- P1 要立刻处理的严重告警,可能已经发生了严重的关键业务不可用的问题
- P2 可以延后处理(8-24小时)的告警,可能已经发生了非关键业务不可用的问题,或长期下去,可能会升级为P1的问题
- P3 可以延后处理(1-7天)的告警,可能已经发生了轻微的业务问题
- P4 信息级别的告警,无需处理,一般仅来让大家知道告警信息的接收没有问题,如果长期没有接受到P4的信息,就需要去处理下告警发送的问题
对于不同的告警应该设置不同的告警间隔时间(频率),建议如下
- P0: 10分钟
- P1: 30分钟
- P2: 2小时
- p3: 12小时
- p4: 12小时
注意:
- 下列告警列表,部分告警内容是有阈值的。
- 没有明确列出��阈值的,则不存在阈值, 或者无需关心阈值。
- 告警里面也会有一些建议延后处理的时间点,虽然跟P0-P4的标准延后处理时间有差异。 但按标准的P0-P4的标准来处理也不会有大问题。
告警列表
1. KubeStateMetricsListErrors
-
优先级: P0
-
描述:
-
kube-state-metrics is experiencing errors at an elevated rate in list operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
-
kube-state-metrics 在list操作中遇到错误的频率很高。这很可能导致它无法正确或根本无法公开有关 Kubernetes 对象的指标。
-
-
原因:
- kubernetes集群出现内部问题, 一般是比较复杂的原因。
- 可能是etcd负载过高、etcd所在节点出现了某些问题、 kube-apiserver 负载过高等。
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 可能会因为kubernetes内部问题,进而引起长时间业务故障。
-
解决方法:
- 立刻处理
- 联系ONES技术支持分析, 排除问题的思路:
- 列出关键信息 kubectl get nodes, kubectl -n kube-system get pods -o wide, kubectl -n monitoring get pods -o wide,
- 根据情况,分析pod log 及 kubectl describe 分析状态, 必要情况下,需要进一步分析kubelet。
- 如果是负载过高引起的,使用top nmon 等近实时监控工具,分析高负载的原因,再视具体情况谨慎处理。
2. KubeStateMetricsWatchErrors
-
优先级: P0
-
描述:
- kube-state-metrics is experiencing errors at an elevated rate in watch operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all.
- kube-state-metrics 在 watch 操作中遇到错误的频率很高。这很可能导致它无法正确或根本无法公开有关 Kubernetes 对象的指标。
-
能否自愈:
- 一般情况下不能,需要人工介入
-
原因
3. NodeFilesystemSpaceFillingUp
-
优先级:
- P0: 4小时内耗尽
- P0: 24小时内耗尽
-
描述:
-
Filesystem on $labels.device at $labels.instance has only printf "%.2f" $value % available space left and is filling up.
-
Filesystem is predicted to run out of space within the next 24 hours. (按磁盘消耗的速度,24小时内耗尽)
-
Filesystem is predicted to run out of space within the next 4 hours. (按磁盘消耗的速度,4小时内耗尽)
节点剩余空间不足,即将耗尽。
-
-
原因:
- 可能是前期存在资源规划问题,过度压缩了磁盘大,导致资源不足。
- 可能是业务bug,对于临时文件使用后,没有及时回收或清理。
- 可能是 当前配置 不能够满足 业务数据的增长。
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 一旦耗尽,引起的长时间的存储相关业务不可用。
-
解决方法:
- 根据磁盘剩余空间大小,再决定是马上介入处理 还是 延后到业务低峰期处理(4-24小时内)。
- 磁盘扩容或清理临时文件,扩容时, 可以逐个节点进行扩展。(可以reboot的情况下,不要强制关机)
- 如果是业务临时文件引起的, 反馈到ONES技术支持(必须在技术支持的指引下,谨慎清理临时文件,需慎重,做好备份)
4. NodeFilesystemAlmostOutOfSpace
-
优先级:
- P0: 剩余空间不足5%
- P1: 剩余空间不足15%
-
描述:
- Filesystem has less than $config alertThresholdP1NodeFilesystemOutOfSpace space left.
- Filesystem has less than $config alertThresholdP0NodeFilesystemOutOfSpace space left.
- 文件系统空间余量小于设置的阈值了
-
能否自愈:
- 一般情况下不能,需要人工介入
-
原因
5. NodeNetworkReceiveErrs
-
优先级: P3
-
描述:
- ' $labels.instance interface $labels.device has encountered printf "%.0f" $value receive errors in the last two minutes.'
- 网卡设备 2分钟内产生了较多的 receive 错误
-
原因:
- 某节点网卡、或网络故障、交换器故障、waf拦截。
-
影响:
- 服务不可用持续约2分钟,2分钟后一般情况下能自愈(这两份钟是由k8s自身默认机制决定的)。
-
解决方法:
- 检查网卡状态、排查内网网络问题、waf问题
-
缓解手段:
- 下线故障节点(init 0, 尽量不要直接关机)
响应时机:
如果业务还能够使用, 可以延后到业务低峰期处理(12小时内)。
6. NodeNetworkTransmitErrs
- 优先级: P3
描述:
' $labels.instance interface $labels.device has encountered printf "%.0f" $value transmit errors in the last two minutes.
网卡设备 2分钟内产生了较多的 transmit 错误
原因、影响、解决方发、响应时机, 同上 5. NodeNetworkReceiveErrs
7. KubePodCrashLooping
-
优先级:
- P1:正常情况下都为P1, 特例服务不出现在p1中(比如libroffice)
- P3: 特例,比如第三方工具libroffice等,偶尔会发生自身故障导致重启的,到重启次数超过3时,为P3
-
描述:
- Pod $labels.namespace / $labels.pod ( $labels.container ) is restarting printf "%.2f" $value times / 5 minutes.
- Pod实例重启了
-
原因:
- 进程异常退出
- OOM
- 业务bug(访问空指针且没有捕获异常)
- 资源上限配置过低了
-
能否自愈:
- 一般情况下能自愈
- 特殊情况下,如果5分钟内连续重启超过5次,会引发5分钟-10分钟的服务故障,这时需要人工介入处理。
- 边缘服务可以延后(4-8小时)处理。
- 关键服务需要马上处理。
-
影响:
- 如果是关键服务,会引发服务抖动、短时间卡顿问题。
- 如果是边缘服务,会导致一些异步或非关键功能异常,比如 performance、审计日志、搜索的实时性产生影响。
-
解决方法:
- 关键服务立刻处理
- 边缘服务延后(1-4小时处理)
- 如果确定某类 pod 重启告警需要做降级或屏蔽,需要联系ONES进行评估,再确定处理方案。
8. KubePodNotReady
-
优先级: P1
-
描述:
- Pod $labels.namespace / $labels.pod has been in a non-ready state for longer than 15 minutes.
- Pod 长时间non-ready
-
原因:
- 节点调度出现问题
- 集群资源不足
- 业务升级出现了问题
- 存储出现问题
- kubelet故障
- docker bug
- linux内核故障
- 网络故障
- 部署工具编排bug
-
能否自愈:
- 不能自愈,需要人工介入
-
影响:
- 可能业务升级出现问题
- 有潜在导致服务不可用的风险。
-
解决方法:
- 立刻处理
- 排查思路:
- kubectl -n xxx get pods -o wide
- kubectl -n xxx describe pod xxx
- kubectl -n xxx get node
- kubectl -n xxx describe node xxx
- ping xxx
- journalctl -f
- 处理方法:
- 具体问题具体分析,需要谨慎操作。
- 需要重启对应节点,才能重新加入集群(重启过程由于kubernetes自身组件问题,服务影响在1-2分钟)
- 检查内网网络问题
- 查看内核日志等
9. KubeDeploymentGenerationMismatch
-
优先级: P2
-
描述:
- Deployment generation for $labels.namespace / $labels.deployment does not match, this indicates that the Deployment has failed but has not been rolled back.
-
原因:
- kubernetes集群出现问题,导致deployment 无法完成正常的滚动更新调度问题
- 也可能是部署工具编排 Deployment 的bug。
- 集群资源不足
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 可能会因为kubernetes内部问题,进而引起长时间业务故障。
-
解决方法:
- 延后处理
- 排查思路:
- kubectl get nodes
- kubectl -n kube-system get pods
- kubectl -n xxx get deployment
- kubectl -n xxx describe deployment xxx
- kubectl -n xxx get pods
- kubectl -n xxx describe pod xxxx
- 处理方法:
- 联系ONES进行处理。
10. KubeStatefulSetReplicasMismatch
-
优先级: P2
-
描述:
- StatefulSet $labels.namespace / $labels.statefulset has not matched the expected number of replicas for longer than 15 minutes.
-
原因:
- 同上: 9. KubeDeploymentGenerationMismatch
- 差异:
- kubectl -n xxx get statefulset
- kubectl -n xxx describe statefulset xxx
11. KubeStatefulSetGenerationMismatch
-
优先级: P1
-
描述:
- StatefulSet generation for $labels.namespace / $labels.statefulset does not match, this indicates that the StatefulSet has failed but has not been rolled back.
-
原因:
- 同上: 9. KubeDeploymentGenerationMismatch
- 差异:
- 需要立即处理,因为有状态应用的影响程度比无状态应用要高
- kubectl -n xxx get statefulset
- kubectl -n xxx describe statefulset xxx
12. KubeStatefulSetUpdateNotRolledOut
-
优先级: P1
-
描述:
- StatefulSet $labels.namespace / $labels.statefulset update has not been rolled out.
-
原因:
- 同上: 9. KubeDeploymentGenerationMismatch
- 差异:
- 需要立即处理,因为有状态应用的影响程度比无状态应用要高
- kubectl -n xxx get statefulset
- kubectl -n xxx describe statefulset xxx
13. KubeDaemonSetRolloutStuck
-
优先级: P1
-
描述:
- Only $value | humanizePercentage of the desired Pods of DaemonSet $labels.namespace / $labels.daemonset are scheduled and ready.
-
原因:
- 同上: 9. KubeDeploymentGenerationMismatch
- 差异:
- 需要立即处理,因为daemonset的影响程度比无状态应用要高,并且很多情况下是影响所有节点的
- kubectl -n xxx get daemonset
- kubectl -n xxx describe daemonset xxx
14. KubeContainerWaiting
-
优先级: P3
-
描述:
- Pod $labels.namespace / $labels.pod container $labels.container has been in waiting state for longer than 1 hour.
-
原因:
- 部署问题
- 在等待依赖的中间件、或服务,且对应的中间件或服务长时间没有准备好
- 集群资源不足,导致依赖的中间件、或服务, 间接引发该告警
- 镜像仓库虽然能正常连接,但是拉取镜像的速度过慢,可能限速过于严重。
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 业务可能无法正常更新版本或配置
-
解决方法:
- 延后处理(2-8小时)
- 排查思路:
- kubectl -n xxx describe pods xxx
- kubectl -n xxx get pods xxx -o yaml , 观察是哪个container 卡住
- 处理方法:
- 具体问题,具体分析,解决卡住初始化的问题
15. KubeDaemonSetNotScheduled
-
优先级: P3
-
描述:
- $value Pods of DaemonSet $labels.namespace / $labels.daemonset are not scheduled.'
-
原因:
- 集群调度出现问题
- 可能是集群资源问题
- 可能是docker bug
- 可能是网络故障
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 可能会因为kubernetes内部问题,进而引起长时间业务故障。
-
解决方法:
- 如果业务还能正常访问,则可延后处理,否则立刻处理
- 排查思路:
- kubectl get nodes
- kubectl -n kube-system get pods
- kubectl -n xxx get daemonset
- kubectl -n xxx describe daemonset xxx
- kubectl -n xxx get pods
- kubectl -n xxx describe pod xxxx
- 处理方法:
- 联系ONES进行处理。
16. KubeCronJobRunning
-
优先级: P1
-
描述:
- CronJob $labels.namespace / $labels.cronjob is taking more than 1h to complete.
-
原因:
- MySQL数据迁移时间过长、迁移失败、迁移卡住、死锁
- 某些定时任务执行时间过长
- 业务编排问题
-
能否自愈:
- 一般情况下能够自愈
-
影响:
- 可能会导致 ONES 业务版本更新时数据迁移失败
- 可能会引发集群资源问题,需要随时留意集群的情况,避免发生服务不可用的问题。
-
解决方法:
- 可以延后处理 (2-8小时)
- 耐心等待,但是要注意观察集群的情况或留意新的告警。
17. KubeJobCompletion
-
优先级: P1
-
描述:
- CronJob $labels.namespace / $labels.cronjob is taking more than 1h to complete.
-
原因:
18. KubeJobFailed
-
优先级: P2
-
描述:
- Job $labels.namespace / $labels.job_name failed to complete.
-
原因:
- 同上 16. KubeCronJobRunning
- 差异:
- 可以延后处理 (2-8小时)
- 如果是数据迁移导致的,建议立即处理
19. KubeCPUOvercommit
-
优先级: P1(无法分配更多的cpu给新调度的实例了)
-
描述:
- Cluster has overcommitted CPU resource requests for Pods and cannot tolerate node failure.
-
原因:
- 集群�资源不足
- Pod的资源限制设置过高,无法调度到节点上
-
能否自愈:
- 一般情况下不能资源,需要人工干预
-
解决方法:
- 立即处理
- 增加硬件资源或调整资源限制
20. KubeMemOvercommit
-
优先级: P1 (无法分配更多的内存给新调度的实例了)
-
描述:
- Cluster has overcommitted memory resource requests for Pods and cannot tolerate node failure.
-
原因:
- 集群资源不足
- Pod的资源限制设置过高,无法调度到节点上
-
能否自愈:
- 一般情况下不能自愈,需要人工干预
-
影响:
- 可能会导致服务不可用
-
解决方法:
- 立即处理
- 增加硬件资源或调整资源限制
21. KubeQuotaExceeded
-
优先级: P3 (某类 集群资源 的使用率超过 90% )
-
描述:
- Namespace $labels.namespace is using $value |humanizePercentage of its $labels.resource quota.
-
原因:
- 集群资源(cpu、内存)不�足
- 存储资源不足
-
能否自愈:
- 一般情况下不能自愈,需要人工干预
-
影响:
- 可能会导致服务不可用
-
解决方法:
- 立即处理
- 增加硬件资源或调整资源限制
22. CPUThrottlingHigh
-
优先级:
- P1: Pod cpu使用率超过上限的50%了 (一般情况下系统仍能够使用,但是可能某些服务会卡顿)
- P4: Pod cpu使用率超过上限的25%了(预警)
-
描述:
- ' $value | humanizePercentage throttling of CPU in namespace $labels.namespace for container $labels.container in pod $labels.pod .
- 某些pod的cpu超过警戒线。
-
原因:
- 集群资源(cpu、内存)不足
- 节点负载过高
- pod的cpu设置过低
-
能否自愈:
- 视情况而定,一般能自愈
- 如果出现业务访问故障了,需要人工干预
-
影响:
- 可能会导致服务不可用
- 可能对业务完全无影响
-
解决方法:
- 如果业务有问题了,立即处理
- 如果业务还能正常使用, 可以延后处理(2-8h)
- 增加硬件资源或调整资源限制
23. KubePersistentVolumeUsageCritical
-
优先级:
- P0: 某个数据卷的剩余容量低于3%了
-
描述:
- The PersistentVolume claimed by $labels.persistentvolumeclaim in Namespace $labels.namespace is only $value | humanizePercentage free.
-
原因:
- 卷存储服务出现问题
- 网络故障
- 超过2个实例的磁盘同时损坏
- 被误删节点的磁盘数据
- ceph bug
-
能否自愈:
- 视情况而定,大多数情况不能自愈
- 少数情况能够自愈(比如只是偶发的网络抖动)
-
影响:
- 可能会导致服务不可用
-
解决方法:
- 分析磁盘、网络、ceph问题
- 联系ONES进行处理
24. KubePersistentVolumeFullInFourDays
-
优先级: P1 按趋势,某个数据卷4天内耗尽
-
描述:
- Based on recent sampling, the PersistentVolume claimed by $labels.persistentvolumeclaim in Namespace $labels.namespace is expected to fill up within four days. Currently $value | humanizePercentage is available.
- 磁��盘快满了
-
原因:
- 数据卷快满了
-
能否自愈:
- 不能自愈
-
影响:
- 可能会导致服务不可用
-
解决方法:
- 视情况而定,可能需要立即处理,也可能可以延后处理
- 联系ONES,扩容
25. KubePersistentVolumeErrors
-
优先级: P1
-
描述
- The persistent volume $labels.persistentvolume has status $labels.phase .
-
原因:
- 卷存储服务出现问题
- 网络故障
- 超过2个实例的磁盘同时损坏
- 被误删节点的磁盘数据
- ceph bug
-
能否自愈:
- 视情况而定,大多数情况不能自愈
- 少数情况能够自愈(比如只是偶发的网络抖动)
-
影响:
- 可能会导致服务不可用
-
解决方法:
- 立即处理
- 分析磁盘、网络、ceph问题
- 联系ONES进行处理
26. KubeVersionMismatch
-
优先级: P4
-
描述: There are $value different semantic versions of Kubernetes components running.
-
原因:
- 不同版本的k8s节点放在了同一个集群内
-
能否自愈:
- 视情况而定,大多数情况不能自愈
-
影响:
- 不可以预知, 但是节点调度会受影响, 也会发生一些奇怪的问题。
-
解决方法:
- 立即处理
- 联系ONES进行处理
- kubectl get nodes (关注VERSION)
- kubectl describe nodes xxx
- kubectl cluster-info
27. KubeClientErrors
-
优先级: P4
-
描述: Kubernetes API server client ' $labels.job / $labels.instance ' is experiencing $value | humanizePercentage errors.'
-
原因:
- k8s集群内部出现问题
- api-server证书过期
- 客户端证书过期
-
能否自愈:
- 视情况而定,大多数情况不能自愈
-
影响:
- 不可以预知,只要不出现其他的连带问题,业务一般还能正常使用
-
解决方法:
- 业务有问题则,立即处理
- 业务能够正常访问,可以延后(2-8)小时处理
- 排查证书、集群资源状态、日志,对症下药。
28. ErrorBudgetBurn
-
优先级:
- P0: 滥用程度过高
- P1:滥用程度高
-
描述:
- budget burn
-
原因:
- k8s集群出现内部问题
- kube-apiserver 超载
- master节点资源不足
- 集群规模过大,api-server不堪重负,可能需要做联邦集群了
- kube-apiserver被恶意攻击
- 第三方operator bug,滥用kube-apiserver
-
能否自愈:
- 视情况而定,大多数情况不能自愈
-
影响:
- 不可以预知,只要不出现其他的连带问题,业务一般还能正常使用
-
解决方法:
- 业务有问题则,立即处理
- 业务能够正常访问,可以延后(2-8)小时处理
- 可能需要升级master节点配置。
- 排查攻击源
29. KubeAPILatencyHigh
-
优先级:
- P0: 延迟的99分位超过4秒
- P1:延迟的99分位超过1秒
-
描述:
- api延迟过高
-
原因: 同上 28. ErrorBudgetBurn
30. KubeAPIErrorsHigh
-
优先级:
- P1: 10%的接口错误率
- P2: 5%的接口错误率
- P4: 1%的接口错误率
-
描述:
- api报错过多
-
原因: 同上 28. ErrorBudgetBurn
31. KubeClientCertificateExpiration
-
优先级:
- P0:24小时内证书过期
- P2: 7天内证书过期
-
描述:
- A client certificate used to authenticate to the apiserver is expiring in less than 7.0 days.
-
原因:
- kubenetes 内部自签名证书快过期了
-
能否自愈:
- 不能自愈
-
影响:
- 业务短期内还能正常使用,集群无法执行新的调度, 如果发生新调度,必然引发服务不可用。
-
解决方法:
- 还在证书有效期内,则可以延后处理
- 如果已经超出证书有效期,需要马上处理
- 参考ONES整理的 k8s集群证书更新手册(make cat-k8s-cert 等)
32. KubeAPIDown
-
优先级: P4
-
描述:
- KubeAPI has disappeared from Prometheus target discovery.
-
原因:
- kubenetes 内部出现问题了
-
能否自愈:
- 不能自愈
-
影响:
- 业务短期内还能正常使用,集群无法执行新的调度, 如果发生新调度,必然引发服务不可用。
-
解决方法:
- 业务有问题则,立即处理
- 业务能够正常访问,可以延后(2-8)小时处理
- 排查api-server的状态
- kubectl -n kube-system get pods xxx
- kubectl -n kube-system describe pods xxx
33. KubeNodeNotReadydy
-
优先级: P1
-
描述:
- ' $labels.node has been unready for more than 15 minutes.'
-
原因:
- 节点宕机
- 节点故障
- 节点负载过高,健康检查心跳失效
-
能否自愈:
- 大多数情况下不能自愈
-
影响:
- 如果触发 k8s 集群内部问题,会导致业务长时间不可用
- 如果没有触发 k8s集群内部问题,业务在1-2分钟内可恢复访问
-
解决方法:
- 立即处理
- 排查node的状态
- kubectl get node
- kubectl describe node xxx
- 可能需要重启节点
34. KubeNodeUnreachable
-
优先级: P1
-
描述:
- $labels.node is unreachable and some workloads may be rescheduled.
- Kubernetes 节点无法访问,部分工作负载可能会重新安排
-
原因:
- 节点故障
-
能否自愈:
- 大多数情况下不能自愈
-
影响:
- 如果触发 k8s 集群内部问题,会导致业务长时间不可用
- 如果没有触发 k8s集群内部问题,业务在1-2分钟内可恢复访问
-
解决方法:
- 立即处理
- 排查node的状态
- kubectl get node
- kubectl describe node xxx
- 可能需要重启节点
35. KubeletTooManyPods
-
优先级: P1
-
描述:
- Kubelet ' $labels.node ' is running at $value | humanizePercentage of its Pod capacity.
-
原因:
- 节点上运行了太多的pod,即将超过阈值了
-
能否自愈:
- 大多数情况下不能自愈
-
影响:
- pod的调度会出现问题, 业务虽然还能够正常访问,但是也有些危险了
- 不尽快处理,容易出现服务不可用
-
解决方法:
- 立即处理
- 排查node的状态
- kubectl get node
- kubectl describe node xxx
- 检查 kubelet 配置的 pod数量限制,根据实际情况来选择调整 pod数量上限,或给集群增加新的节点
36. KubeletDown
-
优先级: P1
-
描述:
- Kubelet has disappeared from Prometheus target discovery
-
原因:
- kubelet挂了
- 节点资源耗尽
- 节点负载过高
-
能否自愈:
- 大多数情况下不能自愈
-
影响:
- 这是极端情况了,大多数情况下业务无法正常访问了。
- 注意:不人工介入,业务可能无法自愈。
-
解决方法:
- 立即处理
- systemctl status kubelet
- 重启kubelet、重启节点、排查节点资源消耗情况
37. PrometheusBadConfig
-
优��先级: P1
-
描述:
- Failed Prometheus configuration reload.
-
原因:
- prometheus的告警规则格式错误
-
能否自愈:
- 不能自愈
-
影响:
- 对业务访问无影响
- 监控系统无法正常处理告警了
- 一旦业务在这段时间内出现问题,无法识别问题并发出告警,要留意了
-
解决方法:
- 立即处理
- 如果能够忍受 业务不可用的风险,可以延后处理。
38. PrometheusNotificationQueueRunningFull
-
优先级: P2
-
描述:
- Prometheus alert notification queue predicted to run full in less than 30m.
-
原因:
- 告警队列满了,可能发不出告警了
- 告警接受端出现问题了
- 网络出现问题
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 对业务访问无影响
- 监控系统无法正常处理告警了
- 一旦业务在这段时间内出现问题,无法识别问题并发出告警,要留意了
-
解决方法:
- 立即处理、或延后处理
- 如果能够忍受 业务不可用的风险,可以延后处理。
39. PrometheusErrorSendingAlertsToSomeAlertmanagers
-
优先级: P4
-
描述:
- ' printf "%.1f" $value % errors while sending alerts from Prometheus $labels.namespace/$labels.pod to Alertmanager $labels.alertmanager.'
- Prometheus 在向特定 Alertmanager 发送警报时遇到超过 1% 的错误.
-
原因:
- Prometheus 跟 Alertmanager 之间的网络出现问题了
- Prometheus 配置错误
- Alertmanager 配置错误
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 对业务访问无影响
- 监控系统无法正常处理告警了
- 一旦业务在这段时间内出现问题,无法识别问题并发出告警,要留意了
-
解决方法:
- 可以延后处理(8-24小时)。
- 检查配置、和网络
40. PrometheusErrorSendingAlertsToAnyAlertmanager
-
优先级: P2
-
描述�:
- Prometheus encounters more than 3% errors sending alerts to any Alertmanager.
原因: 同上 39. PrometheusErrorSendingAlertsToSomeAlertmanagers
41. PrometheusNotConnectedToAlertmanagers
-
优先级: P2
-
描述:
- Prometheus is not connected to any Alertmanagers.
原因: 同上 39. PrometheusErrorSendingAlertsToSomeAlertmanagers
42. PrometheusTSDBReloadsFailing
-
优先级: P4
-
描述
- Prometheus has issues reloading blocks from disk.
-
原因:
- Prometheus服务内部问题
- Prometheus配置错误
- 网络故障
- 磁盘故障
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 对业务访问无影响
- 监控系统无法正常处理告警了
- 一旦业务在这段时间内出现问题,无法识别问题并发出告警,要留意了
-
解决方�法:
- 立即处理
- 如果能够忍受 业务不可用的风险,可以延后处理。
43. PrometheusTSDBCompactionsFailing
- 优先级: P4
同上 42. PrometheusTSDBReloadsFailing
44. PrometheusNotIngestingSamples
- 优先级: P4
同上 42. PrometheusTSDBReloadsFailing
45. PrometheusDuplicateTimestamps
- 优先级: P4
同上 42. PrometheusTSDBReloadsFailing
46. PrometheusOutOfOrderTimestamps
- 优先级: P4
同上 42. PrometheusTSDBReloadsFailing
47. PrometheusRemoteStorageFailures
- 优先级: P1
同上 42. PrometheusTSDBReloadsFailing
48. PrometheusRemoteWriteBehind
- 优先级: P2
同上 42. PrometheusTSDBReloadsFailing
49. PrometheusRemoteWriteDesiredShards
- 优先级: P4
同上 42. PrometheusTSDBReloadsFailing
50. PrometheusRuleFailures
-
优先级: P2
-
描述:
- Prometheus is failing rule evaluations.
-
原因:
- prometheus的告警规则格式错误
-
能否自�愈:
- 不能自愈
-
影响:
- 对业务访问无影响
- 监控系统无法正常处理告警了
- 一旦业务在这段时间内出现问题,无法识别问题并发出告警,要留意了
-
解决方法:
- 立即处理
- 如果能够忍受 业务不可用的风险,可以延后处理。
51. PrometheusMissingRuleEvaluations
- 优先级: P4
52. AlertmanagerConfigInconsistent
-
优先级: P4
-
描述:
- The configuration of the instances of the Alertmanager cluster
$labels.serviceare out of sync.
- The configuration of the instances of the Alertmanager cluster
-
原因:
- Alertmanager配置错误
- kubernetes集群触发bug
-
能否自愈:
- 不能自愈
-
影响:
- 对业务访问无影响
- 监控系统无法正常处理告警了
- 一旦业务在这段时间内出现问题,无法发出告警,要留意了
-
解决方法:
- 立即处理
- 如果能够忍受 业务不可用的风险,可以延后处理。
53. AlertmanagerFailedReload
- 优先级: P2
同上: 52. AlertmanagerConfigInconsistent
54. AlertmanagerMembersInconsistent
- 优先级: P2
同上: 52. AlertmanagerConfigInconsistent
55. TargetDown
- 优先级: P4
同上: 52. AlertmanagerConfigInconsistent
56. ClockSkewDetected
-
优先级: P4
-
描述:
- Clock skew detected on node-exporter $labels.namespace / $labels.pod . Ensure NTP is configured correctly on this host.
-
原因:
- 节点时钟错误
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 会引发kubernetes内部问题,业务时间错乱、产生脏数据等。
-
解决方法:
- 立刻处理
- 检查节点系统时间,及时间同步, 修复后,重启对应节点,并清理redis缓存。
57. NodeNetworkInterfaceFlapping
-
优先级: P4
-
描述:
- Network interface " $labels.device " changing it's up status often on node-exporter $labels.namespace / $labels.pod "
-
原因:
- 网络环境出现问题
- 可能是多网卡环境,多网卡的某些网卡网络故障、或硬件故障
- 也可能是 接入了 waf,受waf的影响
58. PrometheusOperatorReconcileErrors
- 优先级: P4
可忽略
59. PrometheusOperatorNodeLookupErrors
- 优先级: P4
可忽略
60. PodHighMemory
-
优先级
- P1: mysql内存超过8G、
- P2:redis内存超过1G、rabbitmq超过1G、project-api超过6G、wiki-api超过2G、devops-api超过1G、oness超过1G
-
描述:
- 各类关键业务、关键中间件的内存暂用过高告警
-
原因:
- 硬件资源不足
- Pod内存上限限制过低
- 业务有内存泄漏
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 业务一般情况下能够自愈,但是可能会有秒级的故障感知。
-
处理方式:
- 硬件资源不足,则升级硬件配置
- Pod内存上限限制过低, 这是可以根据需要合理调整上限。
- 如果硬件资源不足,先扩容硬件,再调整上限
- 业务有内存泄漏,则可以先定期手工执行滚动更新命令 kubectk rollout restart xxx进行缓解,再向 ONES 研发组提bug工单跟进
61. NodeHighMemory
-
优先级
- p1: 内存使用量超过 90%
- P2: 内存使用量在 85%-90%
-
描述:
- 节点内存过高
-
原因:
- 节点资源分配不均
- 某些pod内存泄漏或其他原因占用了太多的内存。
-
能否自愈:
- 一般情况下不能,需要人工介入
-
影响:
- 短期(5-10分钟)内对业务影响较小,但是长时间会引发业务故障。
-
解决方法:
- 立刻处理
- 排查思路:
- kubectl top
- 查看节点pod的负载
- 处理方法:
- 缓解: 把内存占用过高的无状态实例进行手工delete,使其重新调度到空闲的节点上。
- 排查内存消耗问题,再确定处理方式。
- 如果是当前硬件无法承载日益增长的用户量,需要考虑扩容了。
62. ONESMetricsAlert
-
优先级
- p1:
- 2分钟内 project-api报错超过30条
- 5分钟内 CallLeancloudAPIFailed错误超过30条
- 5分钟内 RedisError错误超过1条
- 5分钟内 SendEmailFailed错误超过10条
- 24小时内发送了超过8000封邮件
- P2:
- 2分钟内 project-api报错在10-30条之间
- 5分钟内 CallLeancloudAPIFailed错误在10-30条之间
- 24小时内发送了超过6000封邮件
- 5分钟内产生了NginxUpstreamTimedOut错误
- 2分钟内产生了CanalKafkaError错误(canal连接kafka出现了错误)
- p1:
-
描述:
- 各类业务监控信息
-
原因:
- 各类关键业务、关键中间件 出现故障
- 业务出现bug
-
影响:
- 可能导致部分接口报错
- 可能导致长期服务故障
- 可能导致短时间服务故障
- 可能中间件故障
-
处理方式:
- 立即联系ONES进行处理
- 由ONES根据问题的严重程度,来判断处理方式
- 排查各类关键业务、关键中间件的故障
63. ONESProcessCountWarn
-
优先级:P1
-
原因:
- 节点的进程数量超过15000阈值
-
影响:
- 暂时不会对业务访问照成影响
- 长期不处理,将导致 k8s集群的监控检查机制崩溃,导致业务故障
-
处理方式:
- 立即联系ONES进行处理(处理僵死进程)
64. MysqlMasterCheck
-
默认优先级: P2
-
描述:
- master pod '%s' is not the same as the last one '%s'
-
原因:
- 可能是 mysql 主库故障,自动进行了故障转移,切换到新主库上
- 可能是 实施手工执行了 mysql的优雅切主操作。
- 可能是 旧主库所在节点 负载过高 或出现 底层bug(操作系统内核、docker的bug)
-
影响:
- 业务相关的同步管道,可能中断一小段时间,一般情况下能够管道自己能够自行恢复
-
能否自愈:
- 大多数情况下,都能够自愈, 但是需要运维关注从库的状态,确保从库的同步是正常的。
-
处理方式:
- 检查mysql状态是否正常,执行命令 ./script/mysql/status.sh ones
- 如有异常,如果有异常则需要联系ONES处理
- 需要注意一下 旧主库所在的节点是否正常,如果节点有异常,需要联系ONES处理
65. NamePodCheck
-
默认优先级: P2
-
描述:
- failed to get pod '%s'
- pods '%+v' are on the same node '%s'
- pod name is empty
- pod '%s' role not found
- pod '%s' unhealthy
- pod '%s' node not found
- pod '%s' version not found
-
原因:
- pod '%s' unhealthy
- 可能是在升级ONES版本过程中,mysql有比较大的数据迁移,从库跟主库的binlog偏移量相差过大。
- 可能是MySQL从库bug,或其他原因,导致从库无法继续同步主库的数据。
- kubernetes bug 或 节点负载过高 引起的 调度问题
- pod '%s' unhealthy
-
能否自愈:
- 一般情况下,能够自愈。
-
影响:
- 需要 10-60秒的完成自动的故障转移,期间业务的访问会受到影响。
-
处理方式:
- 检查mysql状态是否正常,执行命令 ./script/mysql/status.sh ones
- 特殊情况处理:
-
- 没有在做ONES版本的期间发送告警
- 需要人工介入分析原因,进行风险排查。(请联系ONES)
-
- 在做ONES版本升级
- 对于pod unhealthy,能够自愈,因为此时从库跟主库的binlog偏移量相差过大,一段时间后,主从同步完成后,则会恢复健康(收到MysqlRcover通知)。
- 如果是其他告警,需要人工介入分析原因,进行风险排查。(请联系ONES) 。
-
66. MysqlFindMaster
-
默认优先级: P2
-
描述:
- master not found
- too many master nodes '%+v'
-
原因:
- mysql主从状态异常
-
能否自愈:
- 一般情况下无法自愈
-
影响:
- mysql无法正常连接或使用
-
处理方式:
- 立即联系ONES进行处理
67. MysqlRcover
-
默认优先级: P4
-
描述:
- Mysql cluster becomes healthy.
-
原因:
- mysql恢复健康通知
-
能否自愈:
- 属于恢复健康的通知
-
影响:
- 无
-
处理方式:
- 无
📄️ Node故障处理
本文介绍关于 k3s/k8s Node节点异常问题的诊断流程、排查思路、常见问题及解决方案。
📄️ POD故障处理
本文介绍关于 k3s/k8s Pod异常问题的诊断流程、排查方法、常见问题及解决方案。
📄️ ONES故障处理
本文介绍关于 ONES 常见场景故障处理及解决方案。
📄️ ONES混沌测试
本文基于混沌工程实践,针对 ONES v6.18.x(K3S HA + Longhorn)的集群环境,通过注入服务中断、网络延迟、资源耗尽等典型故障场景,系统性验证系统容错能力。测试结果已转化为可操作的运维知识库,为日常故障预处置提供现象级参考依据。